
Natural Landscapes: Clouds, Rocks, Flowers, Trees are non-smooth, complex, multi-dimensional.
For trees, clouds and flowers - what are the average color, variance and skew ?
Can you really compare different images in this manner ? with rigid intersections between first order statistics.

Intersections within Hyper-cube Representation Data
Statistical models utilize first order statistics: mean, variance and skew as parameters to reduce the overall complexity observed. "Everything is Miscellaneous" video discusses the features that are disregarded by the models. Relational databases are useful when you already know what the data is, how it is related and what questions you want answered. In large enterprises, data that doesn't fit into existing database schema is thrown away. As more data is generated and aggregated more information is lost, if it doesn't fit into established relational models.
Fuzzy results will remain because statistical models include assumptions about observational data, users, organizations and events. These assumptions will skew results away from reality or as Wall Street says - away from Alpha. Statistics actually erase the data. Search results are better if they are organized by similarity to an archetype; i.e a multidimensional entity - like a user that lives in Seattle with friends from CMU and parents living in Connecticut and all the data that is cross correlated with people, places, events, interests, commodities across space and time. Uni-variate statistics of a users age against other user's age in Seattle will miss important relevant information that makes a particular user interesting. Finding other users like the archetype is what the "New Search" will be able to provide. Due to data cleaning and feature reductions this cannot be accomplished with the current search tool infrastructures currently built.
Therefore we must stop - pause - and think to build systems that mimic human's actual intelligence. This is not AI but instead "infinite" memories that are structured like the human brain with a natural interface defining how humans typically communicate with each other via "imagining", "analogies", associations and connections are pursued from large multidimensional maps.
Imagine an infinite vector of all words, numbers, symbols, images, audio, IoT sensor value etc. For every co-located record of each value within a observational reference frame. i.e. time, geo-location, community, user defined "space", all words from every email, every query typed into Google and its response - becomes a "digital memory" that can be queried for similar entities across all dimensions that exist within all the observations.
How is this different from a relational database ?
Relational databases have a finite, small number of columns, the logic of how the columns may be related are embedded inside of applications that utilize the data to answer questions or generate reports. If a user is an SQL - Structured Query Language user some systems permit complex queries to be issued against the database tables or views. Many OLTP production systems do not allow this to occur as some smart users can generate complex queries that never complete and also constrain database server resources. OLAP data cubes were developed to permit users to examine complex, non-obvious relationships.
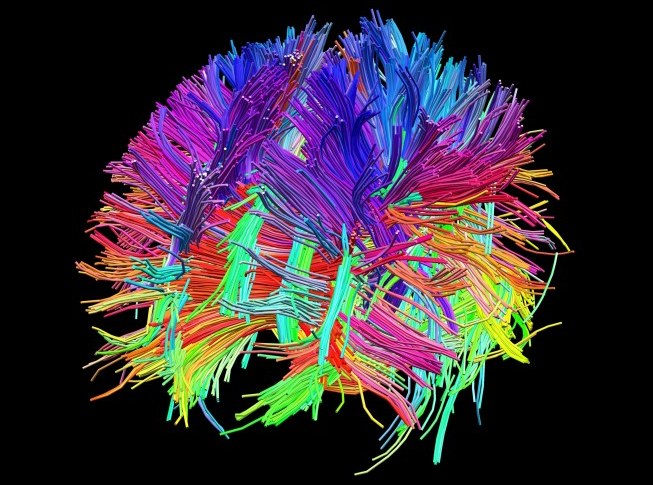
In complex data sets, associative memories can directly link several million entities and attributes. The linking occurs more like how a human brain associates data, as illustrated below in a picture of the human brain indicating some of the neuronal paths that exist. The theory is that they complex pathways connect and associate our memories with our behaviors and control.
The associative memory indexes and correlates across entities and attributes permitting humans to ask questions of the memory like a human might when conversing with another human being. For instance, given this aircraft with the following design, parts configuration and service requests what customers have a similar set of service requests / problems reports ?
I have professionally explored the following domains: acoustics, financials, weather forecasts - general and severe, aircraft dynamics, geo-spatial domains, images, videos, vibrations and complex harmonics in coupled systems (like helicopters), wind turbine dynamics and integration between the sensors and text sources like maintenance event histories, faults, engineering analyses and technical documentation.
Human brain structures look like this:
Actual topology of natural data generates complex topology inside our brains, as the pictures suggest above of trees and flowers illustrate. Looking at several attributes of trees may generate something that looks like. inside our brains:

How does a human decide on similar trees ?
Neuroscience doesn't actually know what these internal topology structures look like. The pictures above are purposefully suggestive of how humans internalize data when we "see" trees.
New search technology coupled with Big Data will enable clearer insights into complex enterprises.
At Boeing my primary assignment had been as technical evangelist for associative memory applications. I was able to re-imagine how to formulate Associative
memory (AM) applications mimic the human memory system as storage and
are able to infer complex correlative data without the need for explicit
rules or embedded inferential logic (like what a programmer would
write). A patent resulted from work where I bested the best statistical models at NASA Glenn
Research Center, UCLA and UPenn PhD Structural Engineers. Both models
and statistics require assumptions whereas memories are composed of
pure correlative observational data.
Associative Memory is a multidimensional map index of correlated entities and attributes. Although sometimes this is imagined to be similar to triple store technology, the associative memory technology actually creates a multidimensional topology of observations. Triple store, RDF graphs are flat instead - SPARQL typically require complex queries to arrive at a result set. And then as an additional step the result set entries must be analyzed, if amenable to a similarity result. Associative memory is a compressed index of entities / attribute observations and the result sets are ordered by similarity.

The above figure illustrates the basic concept of co-associated words. Our human brain stores all the faces, people, places, words, numbers, images, music, voices, videos, etc that we have encountered within our lifetimes. Our recall may not be perfect but our memories permit us to find similarity between everything that we have experienced in a complex, nonlinear way.
"On Intelligence" by Jeff Hawkins is the best accessible book written; it details "theory of brain structure", "experimental evidence that theory is correct" and "systems that can be developed if theory is correct".

More recently, at Analatom I have applied this methodology to correlation of USAF aircraft jet engine dynamics, faults and MX / logbook data. With dual degrees in systems engineering and computer science it has been easy for me to carry forward complex dialog in client facing interactions with business principals and then help them resolve those issues with "memory based methods".
Jet Engine Dynamics for Single Flight
"On Intelligence" by Jeff Hawkins is the best accessible book written; it details "theory of brain structure", "experimental evidence that theory is correct" and "systems that can be developed if theory is correct".

More recently, at Analatom I have applied this methodology to correlation of USAF aircraft jet engine dynamics, faults and MX / logbook data. With dual degrees in systems engineering and computer science it has been easy for me to carry forward complex dialog in client facing interactions with business principals and then help them resolve those issues with "memory based methods".
Jet Engine Dynamics for Single Flight

